- Published on
레거시가 되어버린 프로젝트를 리뉴얼하며 느낀점
- Authors
- Name
휴톰에 2023년 6월 1일에 합류하여 6개월이 지났다. 입사 후 대략 한달간의 교육기간을 거쳐 7월부터 실제 업무를 시작하였다. 입사 후 6개월간의 나의 성장과 느낀점을 정리해보고자 한다.
입사부터 현재까지
휴톰에 합류하기 전의 나의 생각은 다음과 같았다.
- 레거시는 나쁘다.
- 레거시는 잘못된 설계로 인해 발생한다.
- 레거시는 개발자의 능력이 부족(??)해서 발생한다.
- 나는 프론트엔드 개발자다
이러한 생각으로 레거시를 피하고 싶었다.
당시의 개발자들의 능력이 정말 부족해서 였을까? 이 질문에 대한 답은 무조건 NO이다. 그렇다면 왜 레거시가 발생했을까?
이 질문에 대한 답은 레거시는 시간이 지나면서 발생한다. 그 당시의 상황에서는 그것이 최선이었을 것이다. 하지만 현재에는 최선일 수도 아닐 수도 있다.
h-vat도 annotation-tool이라는 프로젝트에서 리뉴얼되었다.
annotation-tool은 2018년부터 개발되었고 클라이언트들의 피드백을 받아 성장해왔고 현재 휴톰의 생산성을 증대시켜주고있는 효자 애플리케이션이다.
휴톰 링크드인에 공개되어있는 annotation-tool의 소개글은 다음과 같다. 근영님이 annotation-tool을 사용하시면서 데이터 매니저로서 비지니스적으로 어떤 기여를 하셨는지 그리고 어떤 효과를 봤는지에 대한 내용이 담겨있다. (좋은 소스를 제공해주신 근영님 감사합니다..!)

annotation-tool을 너무나 잘 사용해주시는 타 부서분들이 계시지만, 그만큼 많은 요구사항들이 들어왔다. 그리고 현재에서는 불가능한 요구사항도 존재해서 리뉴얼을 해보자는 결론이 나왔다.
어떤것을 개선해야하는가?
리뉴얼 진행하기 앞서 어떤것이 문제인가를 점검해보았다.
- 데이터 관련된 비지니스 로직이 프론트엔드에 집중되어 있었다.
- 데이터 모델링에 대한 확장성이 고려되지 않았었다.
- 배포 자동화등 개발환경에서 부족한 점이 존재하였다.
- 서비스를 운영함에 따라 고정 지출 비용이 꽤(?) 많이 발생하였다.
이 문제점들은 개인적인 생각이다. 왜냐하면 그 당시에는 그것이 최선이었기 때문이다. 당시에는 프로토타입을 빠르게 개발하여 클라이언트들의 피드백을 받아야 했기 때문이고, 현재는 기존의 문제점들을 개선해야하는것이 나의 책임이기 때문이다.
데이터 관련된 비지니스 로직이 프론트엔드에 집중되어 있었다.
데이터 관련된 비지니스 로직이 프론트엔드에 집중되어 있었다. 비디오 영상 데이터에대한 정답지를 생성하고 병합하는 작업이 프론트엔드에 존재하였고, 데이터를 적재하는 작업이 백엔드에서보다 프론트엔드에 비중이 컸다.
무슨말인지 잘 이해가 안될 수 있으니 간단히 예시를 들자면 TodoList를 생성하고 수정하는데 수정할때 특정 Todo에대한 수정이 아닌 프론트엔드에서 수정을 완료한 후 전체 TodoList를 백엔드에 전송하는 방식이었다.
이로 인해 프론트엔드에서 데이터를 관리하는 비지니스 로직이 많아졌고, 데이터를 관리하는 비지니스 로직이 많아질수록 유지보수가 어려워졌다.
데이터 모델링에 대한 확장성이 고려되지 않았었다.
데이터는 많아지고 데이터의 타입도 많아지는데 이러한 데이터를 관리하기 위한 데이터 모델링이 고려되지 않았었다. 어노테이터들이 진행하는 작업의 타입과 정답지들의 타입도 많아지고, 학습을 통해 모델이 달라져야하는 상황에서 프론트엔드와 백엔드에 하드코딩 되어있는 기존의 설계에서는 거의 불가능한 상황이었다.
그렇기에 관리자 페이지를 통해 데이터 모델링을 확장 할 수 있도록 설계해야한다고 생각을 하게되었고 유관부서 사람들과 회의를 통해 데이터 모델링을 확장할 수 있도록 설계하게 되었다.
배포 자동화등 개발환경에서 부족한 점이 존재하였다.
배포 자동화등 개발환경에서 부족한 점이 존재하였다.
CI/CD에서 도커 이미지로 빌드하여 Google Artifact Registry에 애플리케이션 서버 이미지를 푸시하고 Google Compute Engine에 배포하는 과정이 수동으로 진행되었다.
현재 규모에서 Production Level에서는 수동으로 하는게 일반적으로 괜찮겠다 싶었다
하지만 Staging Level에서는 통합부터 배포까지 자동화가 되어있어야 한다고 생각하게 되었고 배포환경의 버저닝까지 함께 고려하게 되었다.
서비스를 운영함에 따라 고정 지출 비용이 꽤(?) 많이 발생하였다.
다시한번 말하지만 annotation-tool은 인하우스 솔루션이다. 휴톰 내부에서만 사용되는 솔루션이다. 그러므로 고객은 휴톰의 임직원들이고 더 고려할 수 있다면 단기 아르바이트로 일하는 인력들도 포함된다.
고객 즉 어노테이터들이 24시간 365일 일을 하는가? 그리고 우리의 서버가 과연 24시간 365일 동안 돌아가야할까? 라는 의문이 들었다.
이 의문에 대한 답은 NO이다. 그렇기에 Google Compute Engine과 같은 VPC환경에서 인스턴스가 24시간 365일 동안 돌아가는것은 비용측면에서 매우 비효율적이다.
어떻게 개선할 것인가?
데이터 관련된 비지니스 로직이 프론트엔드에 집중되어 있었다.
이 문제를 해결하기 위해 데이터 관련된 비지니스 로직을 백엔드로 이동시켜야한다고 생각하였다.
프론트엔드는 유저가 보는 화면을 구성하는것에 집중하고, 백엔드는 데이터를 관리하는 비지니스 로직에 집중하도록 설계하였다.
Restful API의 단위를 작게 설계하여 프론트엔드에서 필요한 데이터를 요청하고, 백엔드에서는 요청받은 데이터를 가공하여 응답하는 방식으로 설계하였다.
데이터 모델링에 대한 확장성이 고려되지 않았었다.
이 문제를 해결하기 위해 데이터 모델링을 관리자 페이지를 통해 확장할 수 있도록 설계하였다.
관계형 데이터가 굉장히 많았던 프로젝트였다. 각 데이터가 유기적으로 연결되어있었고 중복되는 데이터를 최소화하고 원자단위로 데이터를 관리하고 있었다.
그래서 nosql인 MongoDB를 사용하던 기존의 방식에서 관계형 데이터베이스인 PostgreSQL로 변경하였다. 그리고 새롭게 데이터베이스 재 설계를 하였다. 각 엔터티들간의 관계를 정의하고, 데이터를 관리하는 비지니스 로직을 백엔드로 이동시키면서 데이터 모델링에 대한 확장성을 고려하였다.
배포 자동화등 개발환경에서 부족한 점이 존재하였다.
이 문제를 해결하기위해 Cloud Function 혹은 Cloud Build등 여러가지 클라우드 서비스를 사용하여 자동화하는것을 고려하였다.
서비스를 운영함에 따라 고정 지출 비용이 꽤(?) 많이 발생하였다.
결론부터 말하자면 Google Cloud Platform의 서비스를 사용하여 비용을 최소화하고자 하였다. 그래서 Google Compute Engine에서 Google Cloud Run으로 변경하였다.
이유는 간단했다. 우리의 서버는 24시간 365일 동안 돌아가지 않아도 된다는것이다. 그렇기에 서버리스 아키텍처를 구상하게되었지만 콜드스타트라는 문제가 발생하였다.
콜드스타트는 서버리스 아키텍처에서 발생하는 문제로, 서버가 쉬고있는 상태에서 요청이 들어오면 서버가 깨어나는 시간이 발생하는 문제이다.
이 문제를 해결하기 위해 고려해볼 수 있던 방법은 세가지 정도가 있었다.
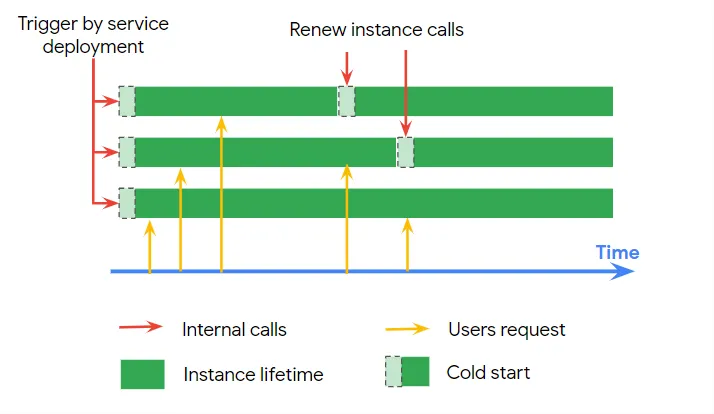
Cloud Run의 min-instances를 사용하여 최소 인스턴스를 유지하는 방법

Cloud Scheduler를 사용하여 주기적으로 요청을 보내는 방법

인스턴스가 종료되는 시점에 알림을 주는 웹훅으로 인스턴스 재 생성으로 인스턴스 무한 생성으로 해결하는 방법
최소 인스턴스를 두는것은 기존의 방식과 비슷한 방법이라고 생각하였고, 루프를 돌아 인스턴스를 재 실행해주는 방법도 재설계의 목적과는 맞지않다고 생각하게 되었다.
그래서 Cloud Scheduler를 사용하여 주기적으로 요청을 보내는 방법으로 설계하였다.
리뉴얼을 진행하면서 나 혹은 h-vat의 코드가 변화한점
스택의 최신화
기존의 프로젝트는 React를 사용하며 Redux 베이스의 프론트엔드로 그리고 Express와 Mongoose를 사용하여 백엔드를 구성하였다.
리뉴얼을 진행하면서 프론트엔드는 React와 React-Query, Zustand를 사용하여 구성하였고, 백엔드는 Nest.js와 Typeorm을 사용하여 구성하였다.
왜 최신화가 필요한지는 다음과 같다.
- 프론트엔드의 경우
React-Query와Zustand를 사용하여 서버상태와 클라이언트 상태관리를 나누어 관리하였다.Redux를 사용하지 않은 이유는Redux를 사용하면서 느꼈던 불편함이 있었고,Redux는 사내의 프론트엔드 개발자 분들이 사용하고 있지 않기도하고, 내가 많이 써본 상태관리 라이브러리가 아니었기때문이다. 나는mobx가 익숙했지만,zustand를 사용하기로 결정하였다. 그 이유는 mobx를 사용하면서 느꼈던 불편함이 있었고,mobx를 사용하면서 느꼈던 불편함은mobx를 사용하려면 코드의 물리적인 양이 너무 많았기 때문이었고,zustand는 React app과 별개로 external store를 사용하기 때문에 리액트 컴포넌트 밖에서도 사용이 가능한 라이브러리 였기 때문이다. - 백엔드의 경우
Nest.js와Typeorm을 사용하여 구성하였다. 가장 큰 변화는MongoDB에서PostgreSQL로 변경하였다는것이다. 그 이유는 관계형 데이터가 많은 구조에서 굳이 nosql을 사용할 필요가 없다고 생각하였고, 관계형 데이터베이스를 쓰며 테이블간의 관계를 정의하고 제약사항을 걸어 관리하는것이 데이터의 무결성을 보장할 수 있었기 때문이다. - 코드베이스가 모두 Javascript에서 Typescript로 변경되었다. 동적 타입 언어에서 정적 타입 언어로 변경되니 런타임에 발생하는 오류를 맞이하는 빈도가 확연히 줄어들어 이직했던 이유인 정적타입언어 사용의 갈망이 해소되었다.
실무에서 백엔드까지 도전해보았다.
처음 h-vat에 투입될때에는 온보딩용으로 신규 백엔드 개발자분과 레거시를 개편해보는 프로젝트로 진행하게되었다. 하지만 내부 솔루션이라서 프로젝트 우선순위가 낮아 함께하던 백엔드 개발자분이 타 프로젝트로 차출되는 상황이 벌어졌고, 사실 이때 음... 답답함이 많이 느껴졌었다.
이직을 하였으나 내가 해야할 일이 무엇인지 명확히 보이지않고, 백엔드 개발자가 없이 api 모킹으로 api 응답이 아마 이런 형태겠지?라는 마음으로 개발을 했었다. 그렇게 개발을 2주간 해보니 내가 왜 잉여자원으로 굴려지게 되는것인지에 대한 의문이 들었었다. 하지만 이런 의문은 빠르게 사라지게되었는데 그 이유는 내가 백엔드 개발까지 맡아서 해보겠다고 요청하였기 때문이었다.
사실 나에게는 정말 쉽지않은 선택이었다. 백엔드개발을 실무에서 해본적이 없는것은 물론이고 서버의 배포는 어떻게 하는것인지? 그리고 데이터베이스의 형상관리와 마이그레이션은 어떻게 하는것인지? 등등 많은 의문이 있었다.
하지만 그냥 해버렸다. 그리고 지금도 계속해서 해나가고있고 1.0버전에서 2.0까지 만들게 되어서 굉장히 뿌듯하다.
반복작업을 자동화하였다.
코드레벨과 배포환경에서의 반복작업을 자동화하였다. 이것은 리뉴얼을 진행하면서 가장 큰 변화였다.
코드레벨에서의 불편함은 아래와 같다
백엔드 개발자가 정의해놓은 Response Body Type과 Request DTO등등등 미리 정의해둔 타입과 객체들이 존재하는 상황에서 왜 프론트엔드 개발자는 또 그걸 프론트엔드 코드베이스에서 작성을하고 변경되면 또 수정을 해야하는지가 항상 의문이었었다.
하지만 이번에는 내가 백엔드 개발자이자 프론트엔드 개발자기도하기에 이런 반복작업을 자동화하였다. 바로 openapi-specification-generator를 사용하여 자동화하였다. 자세한 내용은 지난번에 작성했던 OpenApi Specification Generator 도입 에서 확인이 가능하다.
배포환경에서의 불편함은 아래와 같다
스테이징 서버 배포환경에서의 불편함은 빌드와 테스트까지는 자동화가 되어있었지만, 배포는 수동으로 진행되었다.
그래서 배포를 자동화하였다. Cloud Run을 사용하여 서버리스 아키텍처를 구성하고 배포 자동화를 진행하였다. github actions에서 진행되던 CD를 GCP의 Cloud Build를 사용하여 h-vat-backend 레포지토리의 develop 브랜치에 푸시가 되면 자동으로 빌드를 진행하고, 빌드가 완료되면 Artifact Registry로 Docker 이미지를 푸시하고 그 이미지를 컨테이너화 하여 Cloud Run에 컨테이너기반 배포를 진행하도록 자동화하였다.
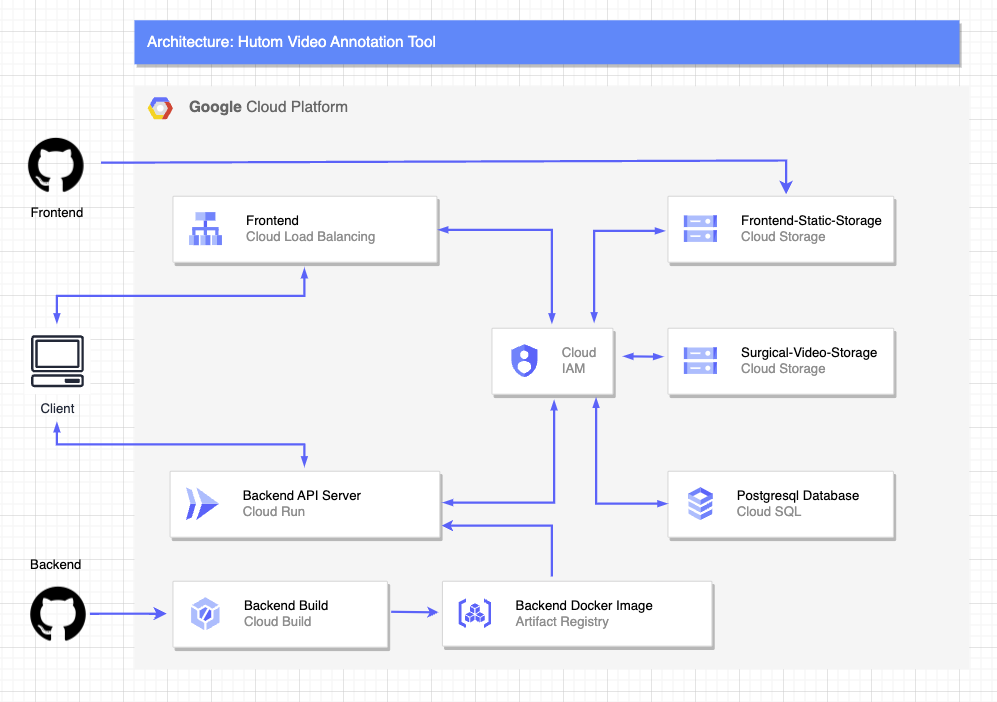
그리고 이런 자동화를 진행하면서 Cloud Build에서 Cloud Run으로 배포하는 과정에서 콜드스타트라는 문제가 발생하였다. 이 문제를 해결하기 위해 Cloud Scheduler를 사용하여 주기적으로 요청을 보내는 방법으로 설계하였다.
미디어 리소스에 대한 접근제한 방식에대한 고려
위의 아키텍처를 보면 중간에 IAM을 거쳐 자격증명이 있는지 확인하고있을것이다.
그렇다 h-vat에서는 수술영상을 관리하는데 이 수술영상은 휴톰의 고객들의 데이터이기 때문에 미디어 리소스에 대한 접근제한 방식에대한 고려가 필요하였다.
이를 위해 고려했던 방법은 4가지였다
- 프락시 서버를 두어 비디오 스트리밍을 진행하는 방법
- API 서버에서 화이트리스트를 관리하여 비디오를 스트리밍하는 방법
- Cloud Storage의 토큰을 사용하여 인바운드 규칙을 뚫는 방법
- Cloud Storage의 Signed URL을 사용하여 비디오의 리소스를 안전하게 관리하는 방법
서버를 거쳐 비디오를 스트리밍하는 방법은 비디오의 용량이 크고, 비디오를 스트리밍하는데에는 서버의 자원이 많이 소모되기도 하며, 리전이 달라 물리적인 거리가 멀어지면 스트리밍이 끊기는 현상이 발생할 수 있다는 문제가 있었다. 그렇기에 이 방법은 고려하지 않았다.
Cloud Storage의 토큰을 사용하는 방법은 h-vat의 서버가 Oauth Provider가 되어야하는 대공사 작업이기에 고려하지 않았다.
Cloud Storage의 Signed URL을 사용하여 비디오의 리소스를 안전하게 관리하는 방법은 비디오의 리소스에 대한 접근을 안전하게 관리할 수 있었고, 비디오의 리소스에 대한 접근을 안전하게 관리할 수 있었기에 이 방법을 선택하였다.
Annotator가 비디오에 접근하여 작업하는 시간을 고려하여 비디오 리소스에 대한 유효기간을 설정하였고, 그렇게 브라우저에서 GCS 버킷을 직접 접근하는것이 아닌 백엔드에서 Signed URL을 생성하여 클라이언트에게 전달하고 클라이언트는 Signed URL을 사용하여 비디오 리소스에 접근하도록 설계하게되어 비디오 리소스에 대한 접근을 안전하게 관리할 수 있었다.
h-vat를 마무리해가며 느낀점
h-vat를 마무리해가며 느낀점은 다음과 같다.
프론트엔드 개발자로의 커리어패스만을 고집하기보단 백엔드 개발도 진행하며 소프트웨어 엔지니어의 커리어 패스를 고려해보는것도 좋다는 생각이 들었다.
내가 다니고있는 회사의 비지니스에 기여하고 다른 부서의 생산성을 높히는데 나 한명의 리소스가 회사에 기여할 수 있는 방법이 무엇인지 고민해보는것도 좋겠다는 생각이 들었다.
h-vat을 리드하며 나는 프론트엔드 개발자로서는 조금 덜 성장했지만 회사에 기여하는 소프트웨어 개발자로서는 성장한 계기가 된거라고 생각하게 된 경험이었다.